1. Projet Congruence
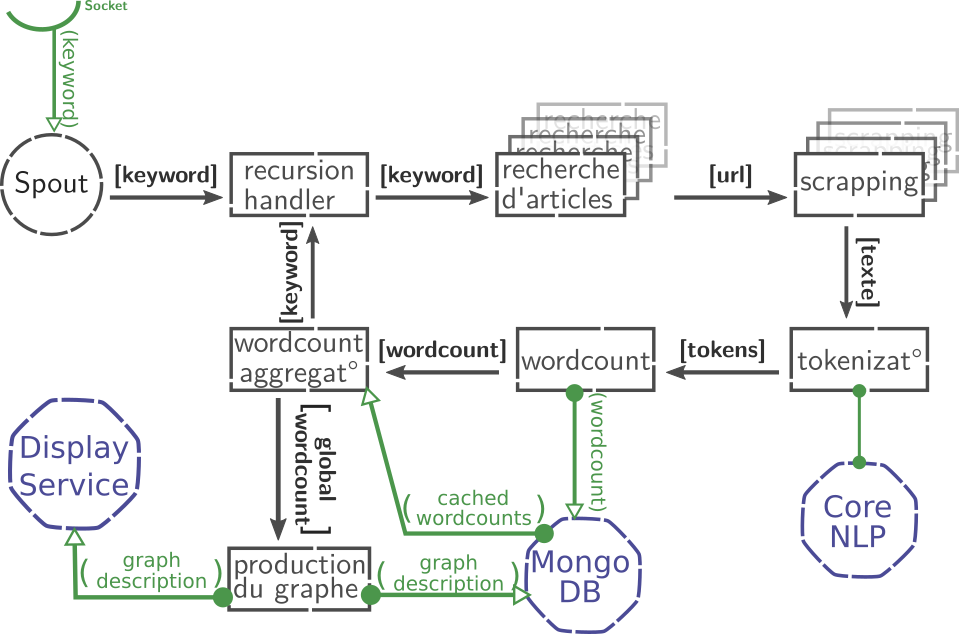
Projet développé en binôme pendant ma formation Big Data. Le but du programme est d'explorer le champ sémantique associé à un mot dans des articles de journaux.
Le programme va tout d'abord effectuer des recherches sur des sites de news, récupérer et parser des articles pour en récupérer le contenu textuel. Ce contenu sera ensuite analysé à l'aide de l'outil CoreNLP, pour en extraire les personnes, organisations et sujets qui apparaissent le plus souvent. Une recherche de nouveaux est ensuite lancée récursivement à partir des sujets les plus fréquents.
La description d'un graphe est générée et mise à jour à chaque fois qu'un article est parsé, où les nœuds sont les mots qui apparaissent le plus souvent dans l'ensemble des articles, et les arrêtes relient les mots qui apparaissent simultanément dans un article.
Une interface web permet d'effectuer une recherche, puis d'afficher le graphe généré.
Outils utilisés
- Apache Storm (avec la librairie python Streamparse) pour la gestion du flux de données.
- MongoDB pour le stockage de donneés.
- Stanford CoreNLP pour l'extraction de tokens.
- Serveur Python/Flask pour l'API.
- HTML/javascript, librairie d3.js pour l'interface web
Ressources
2. Projet Bocal
Projet Java 1.8 visant à implémenter une intelligence artificielle de groupe. Des poissons sont placés dans un bocal, ils doivent éviter les bords du bocal, ainsi que les autres poissons.

3. Projet Yaac
Projet d'implémentation d'une chimie artificielle basée sur des réseaux de Pétri étendus.
Ressources
4. Projet Easy_logging
Librairie de logs pour Ocaml.